Information
Section: What is machine learning?
Goal: Understand a basic machine learning workflow.
Time needed: 10 min
Prerequisites: Curiosity
What is machine learning?¶
Machine learning in general¶
Machine learning describes the study or development of models (algorithms or statistical models) used by a computer to perform a task without explicit instructions. The computer is said to learn from the model, and the outcome or result of the model is the task the computer can perform from the model. The performance of the model represents the accuracy, correctness, or precision of the task performed by the computer, compared to what was expected.
A concrete scenario: say we want to build a model that can predict the weather of tomorrow, given the weather of today. This particular problem is a classification problem (we want to classify the weather of tomorrow into the classes “sunny”, “rainy”, etc…), and the corresponding class (“sunny”, “rainy”) is called a label. Data from the days before are used and fed into the model, which will learn some pattern from the data: for example, if a day was sunny, the next day has high chances to be also sunny. From the data and the patterns learned, the model will compute some predictions for a particular day, given the current data (“As today is a sunny day, tomorrow will be a sunny day.”). These predictions are the result, or the outcome of the model. If the prediction fits the real-world observation (tomorrow is, indeed, a sunny day), the performance of the model is considered good.
Types of machine learning processes¶
One can differentiate two main types of machine learning processes: supervised and unsupervised learning.
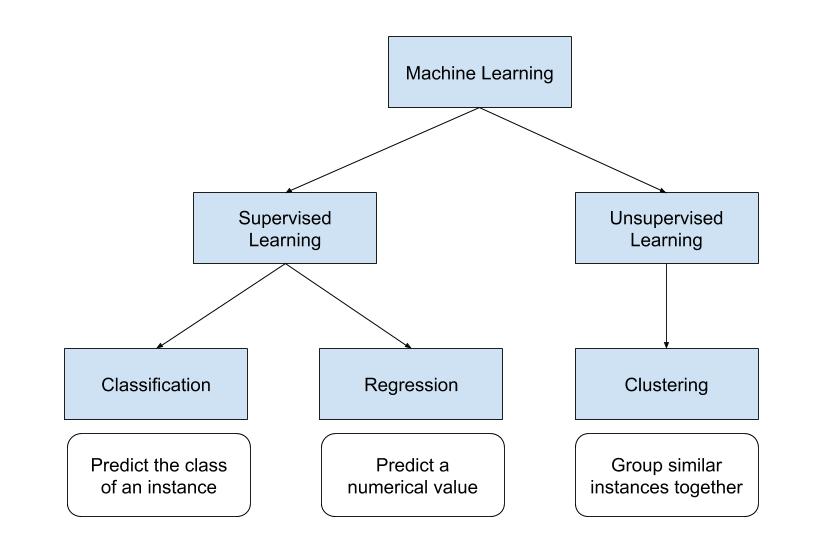
Supervised learning is used with data for which we already know the label (or the class), as it was described with the weather example above. In supervised learning, we find classification tasks (where the label to predict is a class and can be a finite number of different values) and regression tasks (where the label is a real number and can take any value). We will go deeper into these two types of tasks in the next section
.
Unsupervised learning is used with data for which we do not know a label. For example, a task of clustering is unsupervised learning: say you have data from customer’s behavior on a website, and you want to detect customers with similar behavior, a clustering algorithm will be able to perform this task. This type of learning will not be covered in the scope of this course, but if you are interested in learning more about it, you can refer to (1) or (2).
In this course, we will focus on supervised algorithms only.
How are data used in machine learning?¶
In machine learning projects, the main effort is often focused on building a good model enhanced by the outcome of the learning, rather than on the data it is based on. But using training data of poor quality can also distort this outcome: as the algorithm learns from historical data, by nature, data is the central point of a machine learning model.
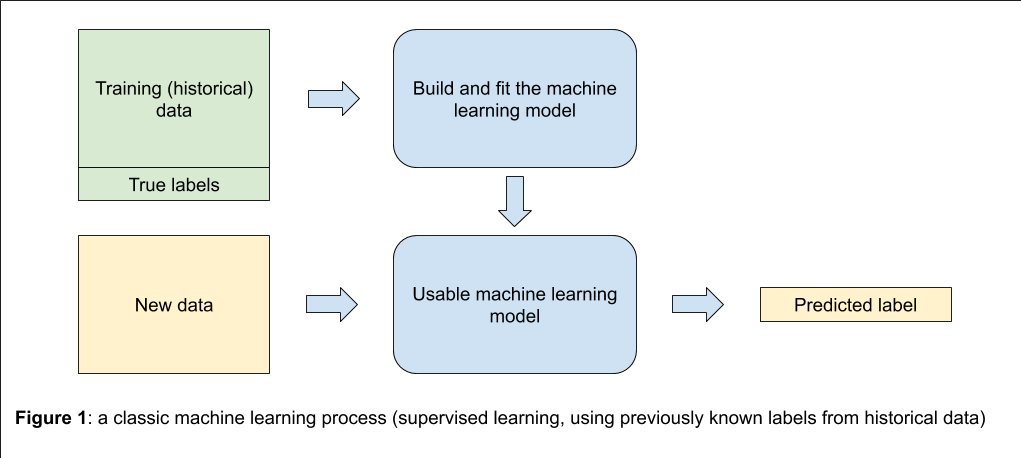
A classic machine learning process is built in two main steps (see Figure 1): first, using historical data gathered beforehand, a model is developed and learns to predict the labels from the data. Afterwards, this model is fed with new data for which we don’t know the outcome, and returns predictions.
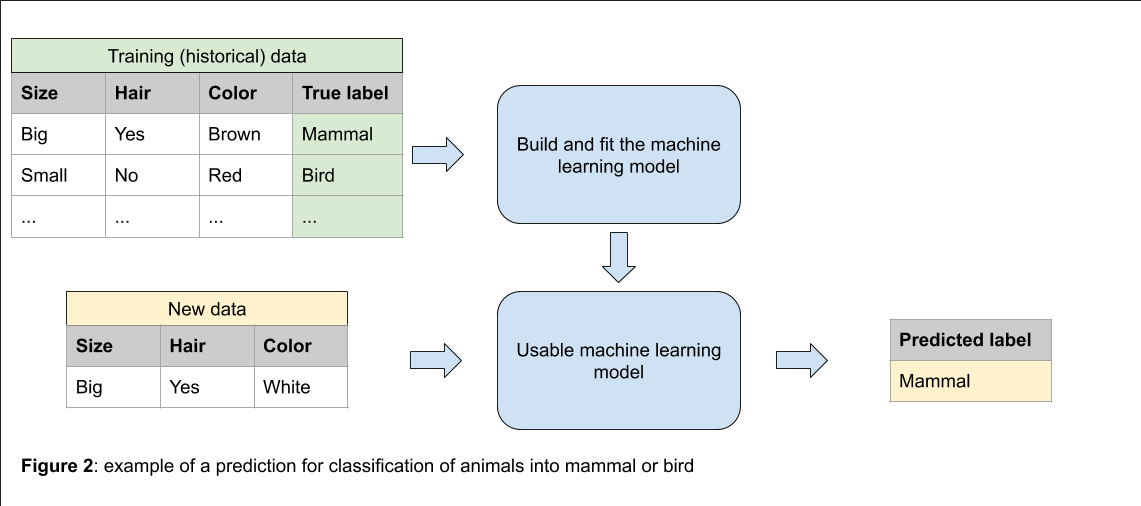
Data are therefore used in two ways here: first, historical data are used to feed and train the model, then new data are used to make the prediction. If these data are of poor quality, with no surprise, the prediction will be affected. The quality of the data can be affected in several ways, for example:
incomplete or missing data: some fields of the dataset are left empty (for example: we want to use geographic coordinates of a ship along its trip, but a whole part of the trip is missing).
incorrect data: some values are wrong in the data (for example: we are using information about the length of a ship, but some values are expressed in meter, others in foot, so the comparison is not directly possible).
biased data: the training data don’t correspond to the predictive data (for example: we use historical data to predict the estimated time of arrival of a ship on a commercial route, but the historical data are 20 years old and during that time, the traffic in the area doubled: the estimation is incorrect because it is based on data that are not representative of the current situation).
The reasons of these errors can be multiple: lack of understanding, sensor error, transmission error, context error, etc…
Let’s see: what did you get from this introduction?
External links¶
(1): “Machine Learning for Humans, Part 3: Unsupervised Learning”, from the Medium website: https://medium.com/machine-learning-for-humans/unsupervised-learning-f45587588294
(2): “Introduction to Unsupervised Learning”, from the Algorithmia website: https://algorithmia.com/blog/introduction-to-unsupervised-learning