Information
Section: Supervised learning used in this course
Goal: Learn one particular machine learning process: supervised learning. Understand how it is used in this course. Get an idea on the basic algorithms used in the course.
Time needed: 10 min
Prerequisites: What is machine learning?
Supervised learning used in this course¶
Classification and regression¶
As we saw in the previous section, supervised learning models use data for which we already know the label, and try to predict it on new unknown data.
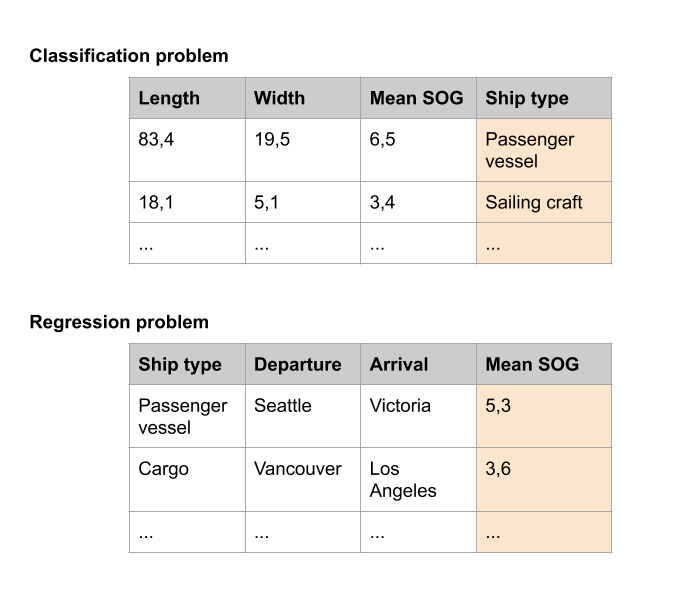
Supervised learning tasks can be of two types: classification and regression. The ground idea stays the same: prediction of an outcome, the only difference is the type of outcome. In classification problems, a class is predicted: the outcome can only take a value from a fixed set of distinct possibilities. In a regression problem, the outcome is a continuous numerical variable and can take any value.
Build and train the model¶
The first step is to gather labeled data to train the model.
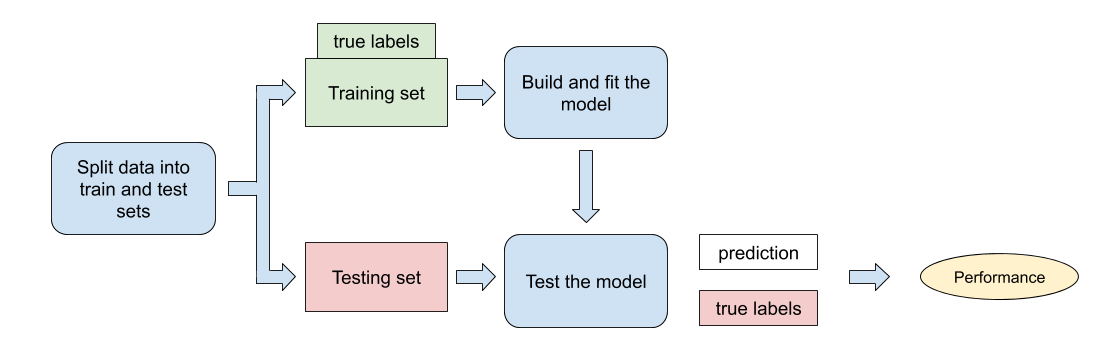
As we want a neutral way of testing the performance of the model, we need to split the available data into two (sometimes more, but we will keep it simple in the scope of this class) different sets:
the training set: this part of the data will be used to train the model
the testing set: this set is left out during the training of the model, and is used for testing the performance: the model predicts the outcome of the data in the testing set, and this outcome is compared with the real outcome that we know from the data
It is important that the training and testing sets do not overlap: as the model learns from the training data, if the same data were used for testing, it would lead to a biased performance result (the model is tested on the same data that were used for it to learn).
Each time we will use a supervised machine learning algorithm in this course, the following steps will be observed:
split the data into training and testing set
build the model using the training set and its true labels
make prediction on the testing set
compare predictions to true labels of the testing set and get performance
Sometimes, when a model has to be specifically adapted to the task, the steps might get a bit more complex (the separation of the training and testing datasets might differ for example), but the base idea stays the same.
Measure of performance¶
There are different ways to measure the performance of a model, depending on its type. In this class, we will use accuracy for a classification model, and mean absolute error (MAE) for a regression one.
Accuracy: percentage of correctly classified instances.
Mean absolute error: average difference between the prediction and the true label.
For more complex problems, the performance measure is usually a custom task as itself.
Baseline¶
For some problems, we do not know in advance if a solution exists. A baseline model is a model that makes predictions using very simple rules. Comparing the results of a complex machine learning model with a basic baseline one is useful to determine if the model is really good, or if the result is due to luck.
Here are a few examples of baseline models:
Classification
Stratified prediction: the model generates prediction respecting the training set’s class distribution. For example, if the training set has 30% of class A and 70% of class B, the baseline model makes random prediction respecting this distribution.
Most frequent: the model always predicts the most frequent label in the training set. If we take the previous example, the baseline model always predicts class B.
Constant: the model always predicts a constant value, provided by the user.
Regression
Mean: the model always predicts the mean value of the training set.
Median: the model always predicts the median value of the training set.
Constant: the model always predicts a constant value specified by the user.
Attributes types¶
In this course, we deal with several types of attributes:
Numeric: this attribute presents as a number (integer or float). This type is commonly used to represent continuous numerical variables (for example, a height, or a price). In
Pandas, a numerical attribute is usually of the typeint64orfloat64.Categorical: this attribute is a class (a fixed set of values). A label is a particular value for the attribute (for example, the attribute can be “animal” and a label would be “bird”, also called a category or a class). In
Pandas, this attribute is of the typecategory.String: this is a chain of characters. In the first chapter (numerical data), we cannot use this attribute as a string and need to convert it to a categorical attribute. In
Pandas, it is of the typeobject.Timestamp: this attribute represents a date and a time. In
Pandas, it is of the typedatetime64[ns].Time difference: this attribute is the difference between two timestamps. In
Pandas, it is represented under the typetimedelta64[ns].