Machine learning algorithms and functions used for numerical prediction¶
This lecture is about data quality, so we do not want to focus too much on the task of prediction, but more on the data themselves. For this reason, the prediction functions have been simplified as much as possible, and we will use some simple algorithms from some Python libraries.
To understand how a simple task of supervised learning is led, refer to the introductory part.
This section is not mandatory to understand the rest of the course, but if you are curious about the functions used for prediction, we will now go through them.
There are 2 kinds of supervised prediction tasks: classification and regression. Here, they will be handled with the same algorithm, only the function used and the way of measuring the performance change. We use a simple K-Nearest-Neighbors (KNN) algorithm for both types of prediction tasks. The KNN algorithm is simple to understand and to implement and usually gives good results, that is why we chose it for this course.
The K-Nearest-Neighbors algorithm¶
The KNN algorithm classifies a new instance based on the idea that “similar objects are close to each other”. The ground idea of the algorithm is to calculate a distance metrics between each instance, and to classify similarly two instances that are close to each other.
Let’s look at this in details, with an example.
Let’s say we want to classify some types of flowers: we have 3 classes or iris flowers (Iris setosa, Iris versicolor and Iris virginica). We have the petal length and width for a few samples of each flower, represented on this graph:
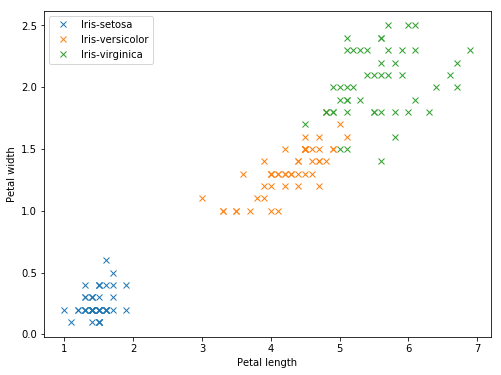
The different types of iris seem easy to distinguish on the graph, based on the petal length and width.
To classify an instance, the KNN algorithm measures the distance of the instance to every other instance in the training dataset. Then, according to the value of K (a parameter of the model that has to be specified by the user), the algorithm then looks at the class of the K instances with the smaller distance to the new instance. The majority class among the K nearest instances is the class that is predicted for the new algorithm. Let’s look together at a small example:
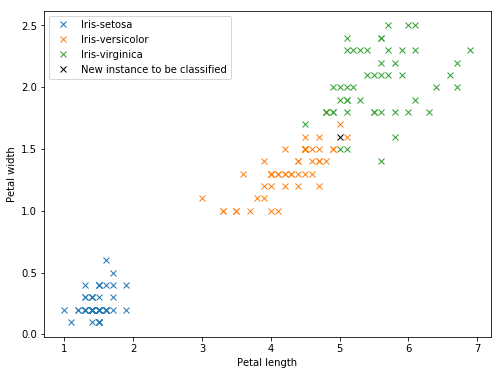
In black, a new instance has been represented: we do not know the class of this instance and want the algorithm to predict it. The model will first find the nearest K instances (in this example, we took K = 5):

The algorithm now will look at the class of these K instances. In our example, we have 3 points of the class Iris-versicolor (orange) and 2 of the class Iris-virginica (green): the majority class of the K nearest neighbors is then Iris-versicolor, and the instance is classified as such.
For a regression problem, the algorithm works the same way, and to predict the value of the new instance, it takes the mean value of the K nearest points.
Regression functions¶
In Python, the library sklearn contains some implementation of the common machine learning algorithms. We use the function KNeighborsRegressor() to build the model.
At first, we split the dataset into training and testing sets with the function train_test_split() from the sklearn library. Then, to avoid any error as the KNN algorithm does not handle missing values, we fill the missing values with 0, using the Pandas function fillna() on the dataframe.
The model is then instanciated, here we take a value of 25 for the parameter K. Once the model is instanciated, we train it with the method fit(). Then we get the predictions on the testing set with the method predict(). Finally, the function returns the predictions and the true labels.
# KNN regression
def knn_regression(df, x, y):
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
x_train, x_test, y_train, y_test = train_test_split(df[x], df[y], test_size = 0.2, random_state = 0)
x_train = x_train.fillna(value = 0)
x_test = x_test.fillna(value = 0)
y_train = y_train.fillna(value = 0)
y_test = y_test.fillna(value = 0)
knn = KNeighborsRegressor(n_neighbors = 25)
knn.fit(x_train, y_train)
predictions = knn.predict(x_test)
return predictions, y_test
We implemented an additional function called knn_reg_train() for the purpose of the exercise. This function is used when we want to specify the training set ourselves. It returns the trained model, on which the user can further make his own predictions with his own testing set.
# KNN regression with specified training set
def knn_reg_train(df_train, x, y):
from sklearn.neighbors import KNeighborsRegressor
x_train = df_train[x].fillna(value = 0)
y_train = df_train[y].fillna(value = 0)
knn = KNeighborsRegressor(n_neighbors = 25)
knn.fit(x_train, y_train)
return knn
Finally, we also needed to implement a baseline model for the exercise. We use the function DummyRegressor() from the sklearn library with the parameter strategy = mean: each prediction will take the mean value of the predicted attribute in the training set. The rest of the implementation is similar to what we have done in the other functions before.
# Baseline for regression
def baseline_reg(df, x, y):
from sklearn.model_selection import train_test_split
from sklearn.dummy import DummyRegressor
x_train, x_test, y_train, y_test = train_test_split(df[x], df[y], test_size = 0.2, random_state = 0)
x_train = x_train.fillna(value = 0)
x_test = x_test.fillna(value = 0)
y_train = y_train.fillna(value = 0)
y_test = y_test.fillna(value = 0)
dummy = DummyRegressor(strategy = 'mean')
dummy.fit(x_train, y_train)
predictions = dummy.predict(x_test)
return predictions, y_test
Classification function¶
For the classification, we work the same way as for the regression function. Except we do not fill the missing values, because we cannot create a new class on the data.
The model used here is KNeighborsClassifier() from the sklearn library.
# KNN classification
def knn_classification(df, x, y):
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
x_train, x_test, y_train, y_test = train_test_split(df[x], df[y], test_size = 0.2, random_state = 0)
knn = KNeighborsClassifier(n_neighbors = 25)
knn.fit(x_train, y_train)
predictions = knn.predict(x_test)
return predictions, y_test