Information
Section: Sentiment analysis in Tweets
Goal: Understand the problem of opinion mining or sentiment analysis with Tweets and how it is handled by machine learning.
Time needed: 40 min
Prerequisites: None
Sentiment analysis in Tweets¶
Concept and examples¶
Tweets and social networks in general have the great advantage of offering a lot of accessible data, usable for many tasks and researches. On Twitter for example, it is easy to collect tweets regarding a brand to analyze the perception of it by the public. This process is also called “opinion mining” and is widely used and researched.
In this particular example of sentiment analysis in Tweets, we want to build a model able to classify each Tweet into one of 2 categories: positive and negative. This kind of classification allows to get the overall expressed satisfaction on social media for a set of selected Tweets (for example, Tweets about a new product). The text is analyzed by the bag-of-words method, explained here after. The kind of preprocessing that we use on the text might greatly impact the results.
Besides offering large amounts of data, social networks come with the difficulty that the language used is usually not normalized, with the use of slang, spelling mistakes, emojis and other noise in the data, making it hard to process by a text analysis model. That is the reason why we first need to apply some preprocessing techniques.
We will go through the steps with the following Tweet examples (found with a search about #Christmas):
Hospitalizations from COVID-19 have increased nearly 90% and California officials say they could triple by Christmas. https://t.co/hrBnP04HnB
— KRON4 News (@kron4news) December 1, 2020
Something for the afternoon slump / journey home / after school / cooking dinner ... a special 30 minute mix of cool Christmas tunes intercut with Christmas film samples and scratching @BBCSounds https://t.co/rHovIA3u5e
— Chris Hawkins (@ChrisHawkinsUK) December 1, 2020
This happened in Adelaide the other day. #koala #Adelaide https://t.co/vAQFkd5r7q
— 893LAFM (@893lafm) December 9, 2020
Algorithm used and text classification¶
Supervised training and bag of words method¶
With labelled data (supervised training), a model can identify the positive and negative words according to a score. For example, if we want to do opinion mining about a product on Twitter, it is easier if we already have access to some labelled data, for example, a list of customer reviews with a score rating, from another website. By matching the score and the reviews, the model will be able to extract the words that are most often used for positive or negative ratings. This process is known as a “bag-of-words” model: each word is treated separately as a single instance, and the model does not process the grammar or the syntax of the sentence. This is an easy way to deal with text analysis.
Let’s understand this with an example (note: this example is imaginative and not reproducible as it is). Here, we took some food reviews together with a score, all written by customers, on the platform Amazon. From this data and the score, the model determined the most common words in positive (4 or 5 scored) and in negative (1 or 2 scored) reviews. Based on those lists of words, the model can now label new unseen reviews into positive or negative, depending on which words are present in it.
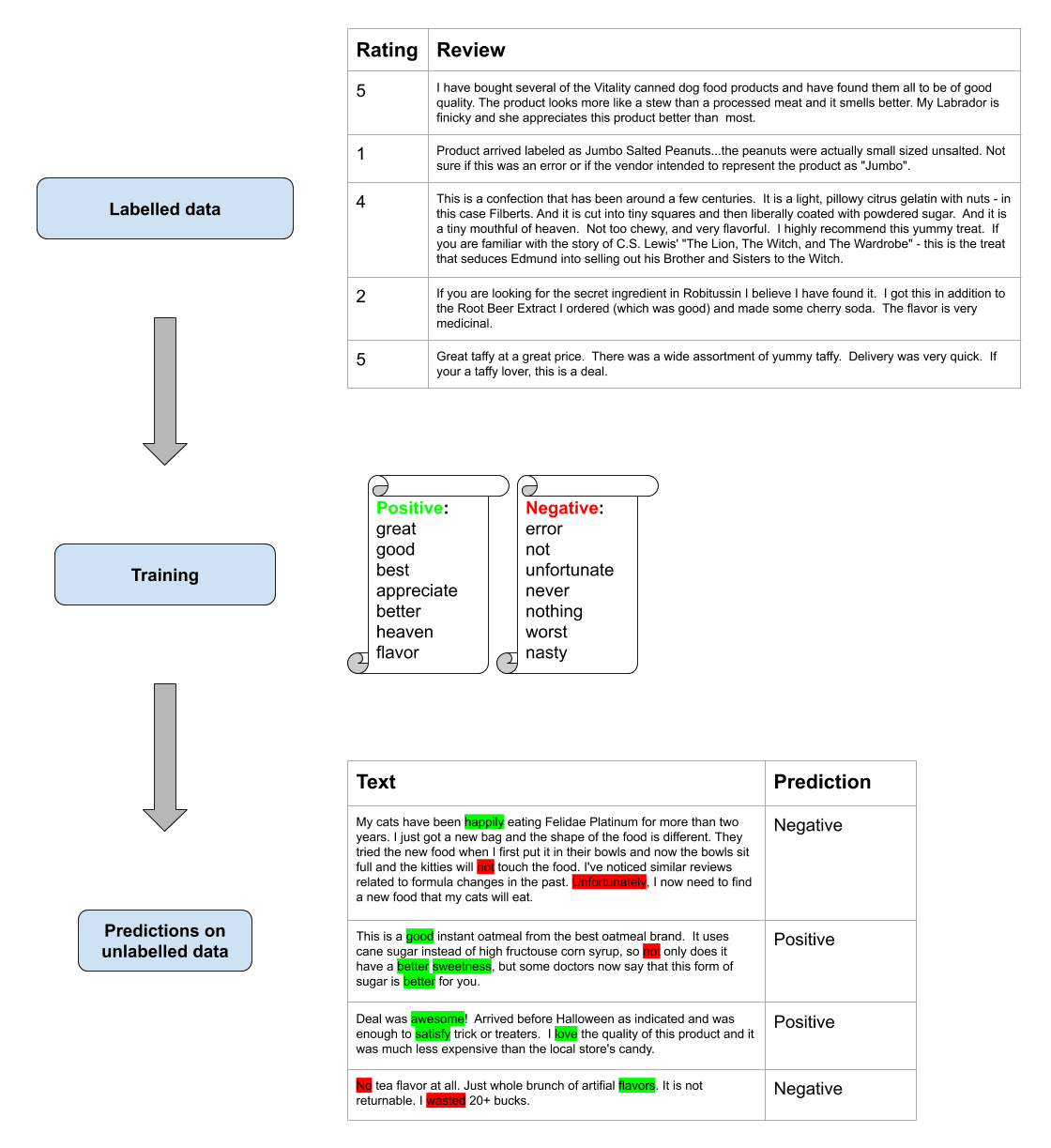 Data from Kaggle “Amazon Fine Food Reviews” and accessible here.
Data from Kaggle “Amazon Fine Food Reviews” and accessible here.
If the data is available, this step can probably give better results as it is focused on a particular product or brand, giving more targetted results.
If the data is not available, it is possible to use models that are already trained, with a list of positive or negative words.
Note: this is one possibility to deal with text analysis, but other methods exist, of course.
Tokenization¶
Tokenization is the process of separating a sentence or a text into smaller parts. Mostly, we want to tokenize the text into words, to be able to analyze each word separately.
A tokenization method takes a text and gives a list of the words that the text contains.
There are several methods to do that.
The simplest is the built-in method split() used on a string. It separates a string into words, separated by a space. This, however, does not allow to separate punctuation. Depending on the cleaning process in use, that we detail in the next pages, this can be of importance or not.
Some libraries have more advanced functions for tokenization. For example, the library NLTK has the function word_tokenize, which is able to separate punctuation as well.
# With the built-in method split()
review = "I have bought several of the Vitality canned dog food products and have found them all to be of good quality. The product looks more like a stew than a processed meat and it smells better. My Labrador is finicky and she appreciates this product better than most."
print(review)
tokens = review.split()
print(tokens)
I have bought several of the Vitality canned dog food products and have found them all to be of good quality. The product looks more like a stew than a processed meat and it smells better. My Labrador is finicky and she appreciates this product better than most.
['I', 'have', 'bought', 'several', 'of', 'the', 'Vitality', 'canned', 'dog', 'food', 'products', 'and', 'have', 'found', 'them', 'all', 'to', 'be', 'of', 'good', 'quality.', 'The', 'product', 'looks', 'more', 'like', 'a', 'stew', 'than', 'a', 'processed', 'meat', 'and', 'it', 'smells', 'better.', 'My', 'Labrador', 'is', 'finicky', 'and', 'she', 'appreciates', 'this', 'product', 'better', 'than', 'most.']
# With the library nltk
from nltk import word_tokenize
review = "I have bought several of the Vitality canned dog food products and have found them all to be of good quality. The product looks more like a stew than a processed meat and it smells better. My Labrador is finicky and she appreciates this product better than most."
print(review)
tokens = word_tokenize(review)
print(tokens)
I have bought several of the Vitality canned dog food products and have found them all to be of good quality. The product looks more like a stew than a processed meat and it smells better. My Labrador is finicky and she appreciates this product better than most.
['I', 'have', 'bought', 'several', 'of', 'the', 'Vitality', 'canned', 'dog', 'food', 'products', 'and', 'have', 'found', 'them', 'all', 'to', 'be', 'of', 'good', 'quality', '.', 'The', 'product', 'looks', 'more', 'like', 'a', 'stew', 'than', 'a', 'processed', 'meat', 'and', 'it', 'smells', 'better', '.', 'My', 'Labrador', 'is', 'finicky', 'and', 'she', 'appreciates', 'this', 'product', 'better', 'than', 'most', '.']
Go onto the next page to learn how this text can be preprocessed before tokenization, for a better result of the analysis.
Quiz¶
from IPython.display import IFrame
IFrame("https://blog.hoou.de/wp-admin/admin-ajax.php?action=h5p_embed&id=65", "959", "332")
References¶
Arpita et al., 2020, Data Cleaning of Raw Tweets for Sentiment Analysis, 2020 Indo – Taiwan 2nd International Conference on Computing, Analytics and Networks (Indo-Taiwan ICAN)
towardsdatascience.com, 2020, A Beginner’s Guide to Sentiment Analysis with Python, online, accessed 04.12.2020
Data: Kaggle, Amazon Fine Food Reviews (https://www.kaggle.com/snap/amazon-fine-food-reviews?select=Reviews.csv)